最初のOCRは文字化けだらけだった
子どもの読み聞かせから始まったこのプロジェクト。手持ちの小説を音声化するには、まずテキストを取り出す必要がある。紙の本を撮影してPDF化し、定番のTesseractに読ませてみたら——返ってきたのはアルファベットの羅列だった。縦書き文書を横書きモードで読み込んでいたのが原因だった。

やってみた理由
PDFの本を音声化するには、まずテキストを取り出す必要がある。自分の場合、手元にある小説は紙の本かKindleで購入したもの。紙の本はスマホで撮影してPDF化、KindleはPC画面をスクショしてPDF化している。絵本1冊くらいの文字量であれば直接入力でいいが、複数冊や小説の文字量になるとそうはいかない。どちらもスキャン画像ベースなので、コピペでテキストを取れない。つまりOCR(光学文字認識)が最初の関門になる。
ここでテキストの品質が悪ければ、後段のLLM校正もTTS読み上げもすべて破綻する。パイプラインの最上流だからこそ、OCRの精度は妥協できない。
やったこと
Phase 1:Tesseract / ocrmypdf で始めた
最初に選んだのは、OCRの定番である Tesseract(ocrmypdf経由)だった。
選んだ理由はシンプルで:
- OSSで最も有名なOCRエンジン
- 日本語の学習済みモデル(
jpn)がある - CPU動作でセットアップが簡単
- ocrmypdfでPDFからの一括処理ができる
動作確認には、著作権切れの「吾輩は猫である」(青空文庫)を縦書きPDF化したテストデータを使った。実装は ops/steps/ocr.sh(143行)に書いた。ocrmypdf 15.2.0 + Tesseract 5.3.4の構成で、日本語+英語(jpn+eng)を指定。テキストレイヤーがあるPDFにはpdftotext、スキャンPDFにはOCRを実行する2段構成にした。
さらに、GPU OCR(PaddleOCR、EasyOCRなど)への移行も検討したが、「高コスト・低ROI」と判断して見送り、ADR(Architecture Decision Record)として「OCRはCPUのまま」と明文化した。
Phase 2:YomiToku の評価と導入
Tesseractの結果が壊滅的だったため(後述)、日本語特化のOCRエンジンを探した。見つけたのが YomiToku——日本語文書に特化したGPUベースのOCRエンジンだ。
- NGC PyTorchコンテナ(25.03-py3)上にDockerで構築
- onnxruntime-gpu 1.20.1 + yomitoku 0.11.0
- RTX 5090のGPUを活かしてCUDA推論
最初はPython APIを直接叩こうとしたが、入力形式の問題(strを渡してるのにnumpy arrayが必要)でハマった。結局CLIラッパー方式(yomitoku <dir> -f md -o <outdir> -d cuda)に切り替えて動作確認が取れた。
Phase 3:Tesseract全廃・YomiToku一本化
504ページの小説(26チャンク分割)でTesseractとYomiTokuを比較し、Tesseractを完全削除してYomiToku一本化を決断した。
削除したもの:
ops/steps/ocr.sh(Tesseractパイプライン全体)ADR-ocr-gpu.md(CPU-onlyの設計判断文書)--force-ocrオプション、AG_OCR_FORCE環境変数
Phase 4:OCR後処理の改善
YomiTokuで精度の良いテキストが取れるようになったが、そのままだとLLMやTTSに渡すには不十分だった。以下の後処理パイプラインを構築した:
YomiToku (Markdown出力)
→ normalize_ocr :HTMLタグ除去 + ルビ抽出
→ sentence_struct:OCR改行の結合 + 一文一行化
→ (ここからLLM処理へ)特に苦労したのが sentence_struct(文構造化)だ。OCRは物理的な列幅で改行を入れるため、文の途中でぶった切られる。これをLLMに渡すと、OCR誤字の修正よりも行構造の解釈にトークンを消費してしまう。
sentence_structでは「段落バッファ方式」を採用し、文末記号(。!?」など)が現れるまで行を蓄積してから出力する。さらに「」『』内のピリオドでは分割しない引用符認識も実装した。
結果
Tesseract の出力(惨憺たる結果)
10ページのテストで:
- 文字数: 512文字(基準1,000文字以上 → FAIL)
- 日本語比率: 6.2%(基準10%以上 → FAIL)
- 精度: Gemini評価で 65%
そして26チャンクの本番テストでは 14/26チャンクがFAIL。「吾輩は猫である」のテストPDFですら、出力はこんな有様だった:
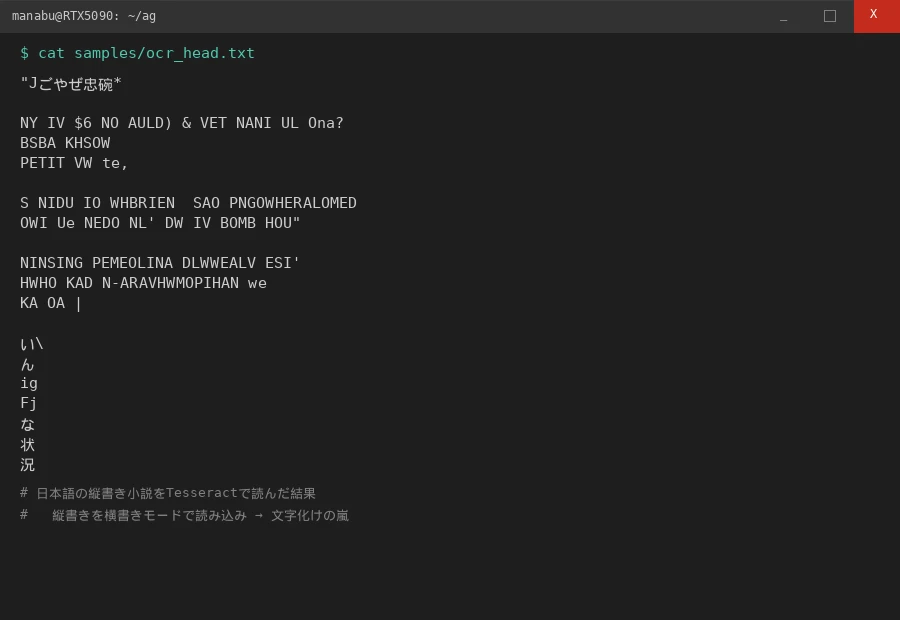
「Jごやぜ忠碗*
NY IV $6 NO AULD) & VET NANI UL Ona?
BSBA KHSOW
PETIT VW te,日本語の小説なのに、出てくるのはアルファベットと記号の羅列。縦書きの列を横に読もうとした結果、漢字のストロークが英字や記号に誤認識されている。原文の面影すらない。
YomiToku の出力
同じ504ページの小説で:
- 26/26チャンク:全PASS
- CER(文字エラー率):5%未満
- 縦書き、ルビ、複雑なレイアウトすべて対応
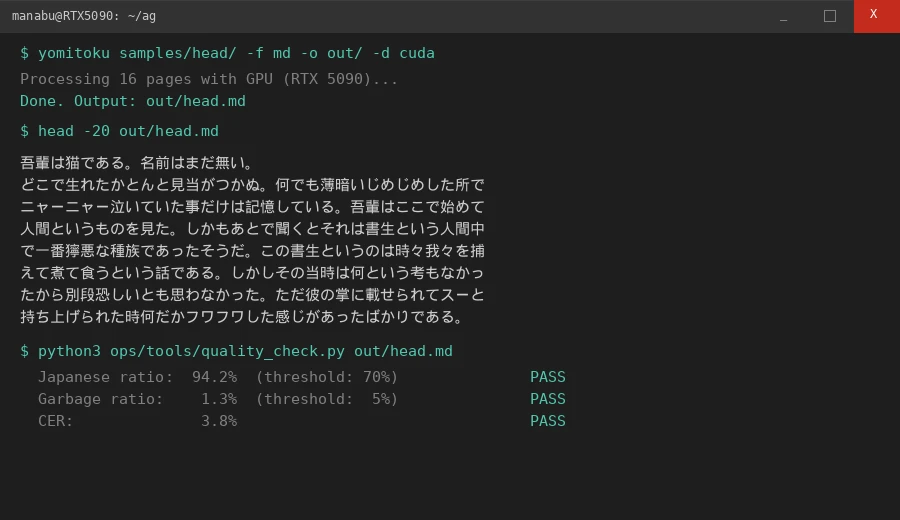
品質チェックの基準(日本語比率70%以上、ガベッジ5%以下)をクリアし、後段のLLM校正に渡せるレベルのテキストが安定して出るようになった。
うまくいった点
- YomiTokuの日本語特化が効いた — Tesseractは多言語汎用エンジンのため、日本語の縦書きへの対応が弱かった。YomiTokuは日本語文書のために作られたエンジンで、縦書き・ルビ・複雑なレイアウトをネイティブに理解する
- Docker化による再現性 — YomiTokuをNGCコンテナ上にDocker化したことで、環境依存の問題が消えた。
docker compose run --rmのオンデマンド実行で、GPUメモリも使い終わったら即解放される - ルビ情報の自動抽出 — YomiTokuはHTMLルビ形式で出力してくれる。これをnormalize_ocrで抽出し、読み辞書に自動登録する仕組みを作った。「異世界」「魔導具」のような作品固有の難読語も、OCRがルビを読み取ってくれれば自動で辞書に入る
- 段階的な品質ゲート — 各ステップにレポート出力と品質チェックを入れた。問題があれば早期に検出でき、壊れたテキストがそのままTTSに流れることを防いでいる
失敗・課題
- Tesseractへの過信 — 「定番のOCRエンジンなら日本語もそこそこ読めるだろう」という思い込みがそもそもの失敗だった。根本原因は縦書きの文書を横書きモードで読み込んでいたこと。Tesseractは横書きの欧文テキスト向けに最適化されており、縦書きのページセグメンテーションが列を正しく認識できず、複数の縦列を横に読もうとして文字をバラバラに切り刻む。「吾輩は猫である」のテストPDFですらまともに読めなかった
- GPU要件の見落とし — RTX 5090(Blackwell、sm_120)はPyTorch 2.7以上が必須。YomiTokuのDocker環境を構築する際、CUDAアーキテクチャの互換性でハマった。NGC 25.03-py3コンテナで解決したが、GPU世代の制約は最初から把握しておくべきだった
- OCR出力の行構造問題 — YomiTokuで正確なテキストが取れても、OCR特有の「物理列幅での改行」が残る。sentence_structの実装に想定以上の工数がかかった
- ルビ情報の取り扱い — 初期実装ではnormalize_ocrでHTMLタグを除去する際、ルビ情報を捨てていた。後からルビが読み辞書の材料になると気づき、タグ除去の前に抽出するようパイプラインを修正した
次にやること
OCRで取り出したテキストは、YomiTokuの精度が高いとはいえ完璧ではない。誤字、脱字、文脈から外れた変換——これらをLLM(大規模言語モデル)で校正するのが次のステップだ。
現在のパイプラインでは、OCR後処理の後に2段階のLLM処理が必要そうだ:
(OCR後処理済みテキスト)
→ llm_fix :OCR誤字の修正(「人」→「入」の誤認識など)
→ llm_prep :TTS向けの最終整形次回の記事では、ローカルLLM(Ollama + qwen3:32b)をどう使ってOCR誤字を直しているか、モデル選定の試行錯誤やプロンプト設計の工夫について書く予定だ。OCRで95%まで持ち上げたテキスト品質を、LLMで限りなく100%に近づける——その泥臭い作業の話になる。
この実験で使った機材 【PR】
- ZOTAC GAMING GeForce RTX 5090 SOLID OC — YomiTokuのCUDA推論に使用。VRAM 32GBのおかげでOCRモデルも余裕で動く